
(Originally posted on my Portuguese blog at rberaldo.com.br)
Do you care about the performance of your applications? Then it’s crucial that you understand what the N + 1 Problem is and know how to identify and fix it.
This is a significant issue that many beginner (and even intermediate) programmers are not familiar with, which can lead to slow applications and a significant loss of performance.
Keep reading this article, and I’ll explain in detail what the N+1 Problem is and how to resolve it.
What Is the N + 1 Problem
To explain this problem, let’s consider a database with two tables: a users table and a posts table, as shown in the image below.
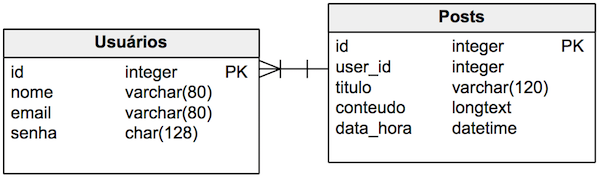
The Users table stores user data such as name, email, password, and so on. The posts table, in addition to post data like title and content, also has a user_id field that references the ID of the user who created the post.
Up to this point, everything seems straightforward. A simple modeling.
Now, imagine you need to create a screen to display all users and the titles of all their posts.
What many would do is:
- Select all users with the following query:
SELECT id, name FROM users; - Then, for each user, execute the following query:
SELECT title FROM posts WHERE user_id = user_id_of_the_user;
If we have 100 users, all these queries will be executed:
SELECT id, name FROM users;
SELECT title FROM posts WHERE user_id = 1;
SELECT title FROM posts WHERE user_id = 2;
SELECT title FROM posts WHERE user_id = 3;
...
SELECT title FROM posts WHERE user_id = 100;
You can see that a total of 101 queries are being executed. This is where you’ll understand the reason for the “N + 1.”
With N representing the number of users, our N is 100, and N+1 is 101, which is the total number of queries executed.
Database queries take time, a lot of time. That’s why you should always aim to minimize the number of queries.
And 101 is definitely not the minimum you’d want for this expected result.
It’s WAY LESS than 101… TOO LESS!
You’ll understand shortly.
Identifying the N + 1 Problem
It’s straightforward to identify this problem. Whenever you find a query inside a loop, it’s likely that the N + 1 problem is occurring.
Let’s take a simple example using PHP:
$PDO = new PDO("connection data here...");
$sql = "SELECT id, name FROM users";
$stmt = $PDO->prepare($sql);
$result = $stmt->execute();
$users = $stmt->fetchAll(PDO::FETCH_ASSOC);
foreach ($users as $user) {
$sql = "SELECT title FROM posts WHERE user_id = :user_id";
$stmt = $PDO->prepare($sql);
$stmt->bindParam(':user_id', $user['id']);
$result = $stmt->execute();
$posts = $stmt->fetchAll(PDO::FETCH_ASSOC);
}
NOTE: If you’re not familiar with PDO, I recommend reading this article.
You can see there’s a query inside the loop. This means that N queries will be executed, with N being the total number of elements in the $users array (which is 100 in our case).
Resolving the N + 1 Problem
Resolving this problem is very simple!
Let’s reduce the number of queries from N + 1 to JUST 2!
We’ll use ONLY TWO QUERIES!
The first query will remain the same as before, responsible for fetching all the users:
SELECT id, name FROM users
However, the second query will use the data from this query to fetch all posts for all users. Then, you can iterate over the array in your program.
The query will use the IN() function in the WHERE clause like this:
SELECT title FROM posts WHERE user_id IN(1, 2, 3, 4, 5, ..., 100);
I’ll modify the previous code and show you how to solve the N+1 Problem for the case we discussed.
$PDO = new PDO("connection here...");
$sql = "SELECT id, name FROM users";
$stmt = $PDO->prepare($sql);
$result = $stmt->execute();
$users = $stmt->fetchAll(PDO::FETCH_ASSOC);
$userIDs = array_column($users, 'id');
$sqlIDs = implode(',', $userIDs);
$sql = sprintf("SELECT title FROM posts WHERE user_id IN(%s)", $sqlIDs);
$stmt = $PDO->prepare($sql);
$result = $stmt->execute();
$posts = $stmt->fetchAll(PDO::FETCH_ASSOC);
Voilà!
Notice that everything remained the same until the creation of the $users variable. The new part appears after this. Let’s analyze it in more detail.
I created the $userIDs variable, which is an array containing all the values from the ‘id’ field in the $users array. This was made easy using the array_column function.
Next, I created the $sqlIDs variable using the implode function. This variable is a string with all the IDs separated by commas, making it usable in the IN function parameter in SQL.
After that, I created the $sql variable to retrieve all posts with just one query.
Analyzing the Performance Gain
Let’s perform a simple performance test to compare the two codes we saw earlier.
The analysis is simple: get the script’s start time, end time, and calculate the difference. To do this, we’ll use the microtime function to get the current time in microseconds and the number_format function to format the time for better readability.
The general code looks like this:
$start = microtime(true);
// code whose performance we want to measure
$end = microtime(true);
$diff = number_format($end - $start, 15, ',', '.');
echo "Total time: " . $diff . PHP_EOL;
To test, I created 100 records in the users table with random values. I also created 1000 random records in the posts table.
Now, let’s look at the results…
The script containing the N + 1 Problem was executed in 0.0198240280 seconds.
In contrast, the script without the problem was executed in 0.0015311241 seconds.
In other words, approximately 13 times faster.
13 TIMES FASTER!
And keep in mind that the example had very little data. A real-world system often has more than 100 users and more than 1000 records related to them.
Why Didn’t I Use JOIN Instead of IN
It’s possible to solve this problem with just one query using JOIN instead of IN, like this:
SELECT u.id, u.name, p.title
FROM users u
INNER JOIN posts p ON p.user_id = u.id
But that doesn’t necessarily mean it will be more efficient.
The focus here is on performance, not just reducing the number of queries.
If each user had only one post, using JOIN could be more efficient. However, if each user has, on average, 100 posts, thousands of duplicated data would be transferred between the database and your application, consuming time and computing resources.



 I'm Roberto Beraldo (or just Beraldo), a passionate PHP Software Developer on a journey to evolve into a versatile DevOps and Cloud Engineer. Bachelor's Degree in Computer Science, with a strong foundation in web development and intermediate DevOps and Cloud Computing knowledge, I am dedicated to bridging the gap between software development and infrastructure management.
I'm Roberto Beraldo (or just Beraldo), a passionate PHP Software Developer on a journey to evolve into a versatile DevOps and Cloud Engineer. Bachelor's Degree in Computer Science, with a strong foundation in web development and intermediate DevOps and Cloud Computing knowledge, I am dedicated to bridging the gap between software development and infrastructure management.
É uma boa dica para iniciantes/intermediários. Mas por que não apresentou uma solução com INNER JOIN? Reduziria para uma consulta só.
Olá, Gabriel
De fato, usar o JOIN reduziria para só uma consulta. Mas nem sempre isso resultará em melhor desempenho.
Atualizei o artigo, adicionando uma seção para comparar JOIN e IN. Veja aqui: http://rberaldo.com.br/o-problema-do-n-mais-1/#in_vs_join
Tenta depois com uma subconsulta no IN
acredito que melhoraria ainda mais o desempenho
Mas vejamos que, para você criar o segundo select (SELECT titulo FROM posts WHERE user_id IN(%s)) você terá que percorrer a lista de usuários 2 vezes, ou então ficar percorrendo o array. E no caso de sua modelagem, se user_id for obrigatório, seria o mesmo que simplesmente colocar “select titulo from posts”, sem cláusula where. Em ambos os casos teria que ser avaliado o desempenho (complexidade do algoritmo) aplicado nas funções de busca de array (para pegar exatamente o nome do usuário com o título de cada post). E outra, se tiver 2000 usuários, mas apenas 100 postaram, teríamos 1900 linhas de usuários carregadas (e sendo repassadas para a segunda consulta) desnecessariamente. Os bancos relacionais otimizam as consultas quando utilizando o join (e ainda mais com os índices corretos). Teria que avaliar bem antes de optar por uma abordagem ou outra.
Bastante interessante, mas tem uma pequena diferença nos códigos produzidos…
Na primeira versão há um agrupamento de postagens por usuário, o que não acontece na segunda versão.
Outro problema é que na segunda versão você não utilizou o bindParam, tudo bem que seus dados vieram do banco direto, mas, porem, todavia contudo, talvez fosse interessante…
Ainda uma última informação, não cheguei a testar, mas acredito que já pode haver um ganho de desempenho se você utilizar o prepare() antes do loop, mais ou menos assim:
...
$users = $stmt->fetchAll( PDO::FETCH_ASSOC );
$sql = "SELECT titulo FROM posts WHERE user_id = :user_id";
$stmt = $PDO->prepare( $sql );
foreach ( $users as $user )
{
$result = $stmt->execute( array( 'user_id' => $user['id'] ) );
...
}
Parabéns pelo artigo, uma sugestão:
Seria interessante adicionar a performance (com as sub-consultas e com o JOIN adicionando um índice no [Posts.user_id]).
Um Abraço!
Parabéns pelo post! Só lembrando que o IN no Oracle por exemplo tem um limite de 1000 itens e caso seja uma aplicação com muitos “usuários” ser tornará inviável o uso da clausula IN.
O resultado impressiona. Muito bom.
Obrigado
Testei aqui com campos VARCHAR deu um erro.
Mas funcionou com campos INT.
Será algum detalhe no sprintf para funcionar com VARCHAR?
Alias aproveitando…
Tive problemas recentemente ao tentar deletar vários registros com IN utilizando campos VARCHAR.
Alguma sugestão?
Obrigado! Abs
Se o campo for Varchar, é preciso colocar o valor entre aspas simples. Pode ser esse o problema.
Depois do implode obtenho assim ‘cafe,milho,arroz’
Para usar com o IN no SQL, qual a dica para vir separado ‘cafe’,’milho’,’arroz’?
Obrigado
Nesse caso, é melhor montar a SQL em um loop.
Veja este meu comentário: http://rberaldo.com.br/inserindo-multiplos-registros-em-tabela-de-banco-de-dados/#comment-2362499911
Legal, vou ler!
Obrigado
Li, mas confesso que não consegui relacionar com a minha dúvida, sobre utilizar string com o IN.
No caso do campo de relacionamento ser string, ao invés de INT, é melhor fazer a consulta dentro do loop, é isso?
Outra coisa, a array_column somente lista os ids do usuário para utilização com WHERE. Para utilizar outros campos do usuário na listagem, nome por exemplo, com a técnica é possível?
Obrigado
Existe uma enorme diferença entre **montar** a consulta dentro do loop e **executar** a consulta dentro do loop. Eu mostrei como montar a consulta no loop. Mas ele só será executada uma vez. Qualquer consulta executada dentro de um loop é sinal de implementação mal feita e problemas de desempenho.
Não entendi sua dúvida com array_columns. Se seu array tem outras colunas, use os nomes delas. Tudo vai depender da estrutura do seu array. A ideia geral é sempre a mesma
Ops, desculpa a demora do retorno.
Legal, entendi sobre montar a consulta.
Vou estudar mais array, e volto com as dúvidas. Abs
Muy buen artículo y super últil. Unas pocas pruebas y debo admitir que siempre se puede mejorar un poco más el código. Saludos y gracias!!
Muito bom Beraldo, obrigado por compartilhar.
O desenho da modelagem está incorreto. O desenho mostra um relacionamento usuário(n) -> post(1), quando na verdade deveria ser o contrário.
Fora isso, belo post, seu blog é muito bom.
Classe A, desempenho é extremamente importante, parabéns, dicas simples e eficientes!
Obrigado!
Desempenho é fundamental, mesmo. E às vezes uma simples dica pode trazer ganhos muito significativos 🙂
Muito bom, parabéns pelas ótimas dicas, sem duvidas o desempenho deve ser levado em conta na hora, já tinha visto este post, voltei só pra rever, parabéns novamente!
Obrigado! 🙂
De fato, desempenho é sempre fundamental. E o usuário fica mais feliz! 😉